Simple and automatic data cleaning in one line of code! It performs one-hot encoding, date & time casting to datetime dtype, detects binary columns, safely convert non-numeric columns to numeric dtypes, cleaning dirty/empty values, normalizing values and removing unwanted columns all in one line of code. Get your data ready for model training and fitting quickly.
AutoDataCleaner
Simple and automatic data cleaning in one line of code! It performs one-hot encoding, converts columns to numeric dtype, cleaning dirty/empty values, normalizes values and removes unwanted columns all in one line of code.
Get your data ready for model training and fitting quickly.
Features
- Uses Pandas DataFrames (no need to learn new syntax)
- One-hot encoding: encodes non-numeric values to one-hot encoding columns
- Converts columns to numeric dtypes: converts text numbers to numeric dtypes see [1] below
- Auto detects binary columns: any column that has two unique values, these values will be replaced with 0 and 1 (e.g.:
['looser', 'winner'] => [0,1]) - Normalization: performs normalization to columns (excludes binary [1/0] columns)
- Cleans Dirty/None/NA/Empty values: replace None values with mean or mode of a column, delete row that has None cell or substitute None values with pre-defined value
- Delete Unwanted Columns: drop and remove unwanted columns (usually this will be the ‘id’ column)
- Converts date, time or datetime columns to datetime dtype
Installation
Using pip
pip install AutoDataCleaner
Cloning repo:
Clone repository and run pip install -e . inside the repository directory
Install from repo directly
Install from repository directly using pip install git+git://github.com/sinkingtitanic/AutoDataCleaner.git#egg=AutoDataCleaner
Quick One-line Usage:
import AutoDataCleaner.AutoDataCleaner as adc
adc.clean_me(dataframe,
detect_binary=True,
numeric_dtype=True,
one_hot=True,
na_cleaner_mode="mean",
normalize=True,
datetime_columns=[],
remove_columns=[],
verbose=True)
Example
>>> import pandas as pd
>>> import AutoDataCleaner.AutoDataCleaner as adc
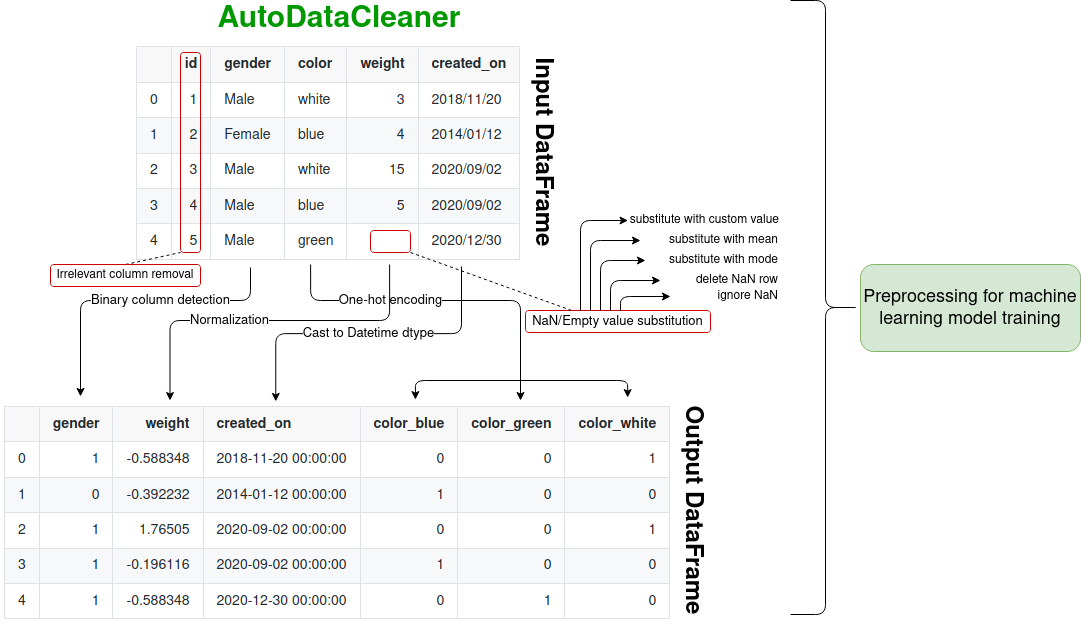
>>> df = pd.DataFrame([
... [1, "Male", "white", 3, "2018/11/20"],
... [2, "Female", "blue", "4", "2014/01/12"],
... [3, "Male", "white", 15, "2020/09/02"],
... [4, "Male", "blue", "5", "2020/09/02"],
... [5, "Male", "green", None, "2020/12/30"]
... ], columns=['id', 'gender', 'color', 'weight', 'created_on'])
>>>
>>> adc.clean_me(df,
... detect_binary=True,
... numeric_dtype=True,
... one_hot=True,
... na_cleaner_mode="mode",
... normalize=True,
... datetime_columns=["created_on"],
... remove_columns=["id"],
... verbose=True)
+++++++++++++++ AUTO DATA CLEANING STARTED ++++++++++++++++
= AutoDataCleaner: Casting datetime columns to datetime dtype...
+ converted column created_on to datetime dtype
= AutoDataCleaner: Performing removal of unwanted columns...
+ removed 1 columns successfully.
= AutoDataCleaner: Performing One-Hot encoding...
+ detected 1 binary columns [['gender']], cells cleaned: 5 cells
= AutoDataCleaner: Converting columns to numeric dtypes when possible...
+ 1 minority (minority means < %25 of 'weight' entries) values that cannot be converted to numeric dtype in column 'weight' have been set to NaN, nan cleaner function will deal with them
+ converted 5 cells to numeric dtypes
= AutoDataCleaner: Performing One-Hot encoding...
+ one-hot encoding done, added 2 new columns
= AutoDataCleaner: Performing None/NA/Empty values cleaning...
+ cleaned the following NaN values: {'weight NaN Values': 1}
= AutoDataCleaner: Performing dataset normalization...
+ normalized 5 cells
+++++++++++++++ AUTO DATA CLEANING FINISHED +++++++++++++++
gender weight created_on color_blue color_green color_white
0 1 -0.588348 2018-11-20 0 0 1
1 0 -0.392232 2014-01-12 1 0 0
2 1 1.765045 2020-09-02 0 0 1
3 1 -0.196116 2020-09-02 1 0 0
4 1 -0.588348 2020-12-30 0 1 0
If you want to pick and choose with more customization, please go to AutoDataCleaner.py (the code is highly documented for your convenience)
Explaining Parameters
adc.clean_me(dataframe, detect_binary=True, one_hot=True, na_cleaner_mode="mean", normalize=True, remove_columns=[], verbose=True)
Parameters & what do they mean
Call the help function adc.help() to output the below instructions
dataframe: input Pandas DataFrame on which the cleaning will be performeddetect_binary: if True, any column that has two unique values, these values will be replaced with 0 and 1 (e.g.: [‘looser’, ‘winner’] => [0,1])numeric_dtype: if True, columns will be converted to numeric dtypes when possible see [1] belowone_hot: if True, all non-numeric columns will be encoded to one-hot columnsna_cleaner_mode: what technique to use when dealing with None/NA/Empty values. Modes:
False: do not consider cleaning na values'remove row': removes rows with a cell that has NA value'mean': substitues empty NA cells with the mean of that column'mode': substitues empty NA cells with the mode of that column'*': any other value will substitute empty NA cells with that particular value passed here
normalize: if True, all non-binray (columns with values 0 or 1 are excluded) columns will be normalized.datetime_columns: a list of columns which contains date or time or datetime entries (important to be announced in this list, otherwisenormalize_dfandconvert_numeric_dffunctions will mess up these columns)remove_columns: list of columns to remove, this is usually non-related featues such as the ID columnverbose: print progress in terminal/cmdreturns: processed and clean Pandas DataFrame
[1] When numeric_dtype is set to True, columns that have strings of numbers (e.g.: “123” instead of 123) will be converted to numeric dtype.
if in a particular column, the values that cannot be converted to numeric dtypes are minority in that column (< 25% of total entries in that column), these
minority non-numeric values in that column will be converted to NaN; then, the NaN cleaner function will handle them according to your settings. See convert_numeric_df() function in AutoDataCleaner.py file for more documentation.
Prediction
In prediction phase, put the examples to be predicted in Pandas DataFrame and run them through adc.clean_me() function with the same parameters you
used during training.
Contribution & Maintenance
This repository is seriously commented for your convenience; please feel free to send me feedback on “[email protected]”, submit an issue or make a pull request!