Data processing for and with foundation models! 🍎 🍋 🌽 ➡️ ➡️🍸 🍹 🍷
[中文主页] | [DJ-Cookbook] | [OperatorZoo] | [API] | [Awesome LLM Data]
Data Processing for and with Foundation Models

![]()
![]()



![]()
![]()
![]()
![]()
Data-Juicer is a one-stop system to process text and multimodal data for and with foundation models (typically LLMs).
We provide a playground with a managed JupyterLab. Try Data-Juicer straight away in your browser! If you find Data-Juicer useful for your research or development, please kindly support us by starting it (then be instantly notified of our new releases) and citing our works.
Platform for AI of Alibaba Cloud (PAI) has cited our work and integrated Data-Juicer into its data processing products. PAI is an AI Native large model and AIGC engineering platform that provides dataset management, computing power management, model tool chain, model development, model training, model deployment, and AI asset management. For documentation on data processing, please refer to: PAI-Data Processing for Large Models.
Data-Juicer is being actively updated and maintained. We will periodically enhance and add more features, data recipes and datasets. We welcome you to join us (via issues, PRs, Slack channel, DingDing group, …), in promoting data-model co-development along with research and applications of foundation models!
[Demo Video] DataJuicer-Agent: Quick start your data processing journey!
https://github.com/user-attachments/assets/6eb726b7-6054-4b0c-905e-506b2b9c7927
[Demo Video] DataJuicer-Sandbox: Better data-model co-dev at a lower cost!
https://github.com/user-attachments/assets/a45f0eee-0f0e-4ffe-9a42-d9a55370089d
News
- 🛠️ [2025-06-04] How to process feedback data in the “era of experience”? We propose Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of LLMs, which leverages Data-Juicer for its data pipelines tailored for RFT scenarios.
- 🎉 [2025-06-04] Our Data-Model Co-development Survey has been accepted by IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)! Welcome to explore and contribute the awesome-list.
- 🔎 [2025-06-04] We introduce DetailMaster: Can Your Text-to-Image Model Handle Long Prompts? A synthetic benchmark revealing notable performance drops despite large models’ proficiency with short descriptions.
- 🎉 [2025-05-06] Our work of Data-Juicer Sandbox has been accepted as a ICML’25 Spotlight (top 2.6% of all submissions)!
- 💡 [2025-03-13] We propose MindGYM: What Matters in Question Synthesis for Thinking-Centric Fine-Tuning? A new data synthesis method that enables large models to self-synthesize high-quality, low-variance data for efficient fine-tuning, (e.g., 16% gain on MathVision using only 400 samples).
- 🤝 [2025-02-28] DJ has been integrated in Ray’s official Ecosystem and Example Gallery. Besides, our patch in DJ2.0 for the streaming JSON reader has been officially integrated by Apache Arrow.
- 🎉 [2025-02-27] Our work on contrastive data synthesis, ImgDiff, has been accepted by CVPR’25!
- 💡 [2025-02-05] We propose a new data selection method, Diversity as a Reward: Fine-Tuning LLMs on a Mixture of Domain-Undetermined Data. It is theoretically informed, via treating diversity as a reward, achieves better overall performance across 7 benchmarks when post-training SOTA LLMs.
- 🚀 [2025-01-11] We release our 2.0 paper, Data-Juicer 2.0: Cloud-Scale Adaptive Data Processing for Foundation Models. It now can process 70B data samples within 2.1h, using 6400 CPU cores on 50 Ray nodes from Alibaba Cloud cluster, and deduplicate 5TB data within 2.8h using 1280 CPU cores on 8 Ray nodes.
- 🛠️ [2025-01-03] We support post-tuning scenarios better, via 20+ related new OPs, and via unified dataset format compatible to LLaMA-Factory and ModelScope-Swift.
History News:
>- [2024-12-17] We propose HumanVBench, which comprises 16 human-centric tasks with synthetic data, benchmarking 22 video-MLLMs’ capabilities from views of inner emotion and outer manifestations. See more details in our paper, and try to evaluate your models with it.
- [2024-11-22] We release DJ v1.0.0, in which we refactored Data-Juicer’s Operator, Dataset, Sandbox and many other modules for better usability, such as supporting fault-tolerant, FastAPI and adaptive resource management.
- [2024-08-25] We give a tutorial about data processing for multimodal LLMs in KDD’2024.
- [2024-08-09] We propose Img-Diff, which enhances the performance of multimodal large language models through contrastive data synthesis, achieving a score that is 12 points higher than GPT-4V on the MMVP benchmark. See more details in our paper, and download the dataset from huggingface and modelscope.
- [2024-07-24] “Tianchi Better Synth Data Synthesis Competition for Multimodal Large Models” — Our 4th data-centric LLM competition has kicked off! Please visit the competition’s official website for more information.
- [2024-07-17] We utilized the Data-Juicer Sandbox Laboratory Suite to systematically optimize data and models through a co-development workflow between data and models, achieving a new top spot on the VBench text-to-video leaderboard. The related achievements have been compiled and published in a paper, and the model has been released on the ModelScope and HuggingFace platforms.
- [2024-07-12] Our awesome list of MLLM-Data has evolved into a systemic survey from model-data co-development perspective. Welcome to explore and contribute!
- [2024-06-01] ModelScope-Sora “Data Directors” creative sprint—Our third data-centric LLM competition has kicked off! Please visit the competition’s official website for more information.
- [2024-03-07] We release Data-Juicer v0.2.0 now!
In this new version, we support more features for multimodal data (including video now), and introduce DJ-SORA to provide open large-scale, high-quality datasets for SORA-like models. - [2024-02-20] We have actively maintained an awesome list of LLM-Data, welcome to visit and contribute!
- [2024-02-05] Our paper has been accepted by SIGMOD’24 industrial track!
- [2024-01-10] Discover new horizons in “Data Mixture”—Our second data-centric LLM competition has kicked off! Please visit the competition’s official website for more information.
- [2024-01-05] We release Data-Juicer v0.1.3 now!
In this new version, we support more Python versions (3.8-3.10), and support multimodal dataset converting/processing (Including texts, images, and audios. More modalities will be supported in the future).
Besides, our paper is also updated to v3. - [2023-10-13] Our first data-centric LLM competition begins! Please
visit the competition’s official websites, FT-Data Ranker (1B Track, 7B Track), for more information.
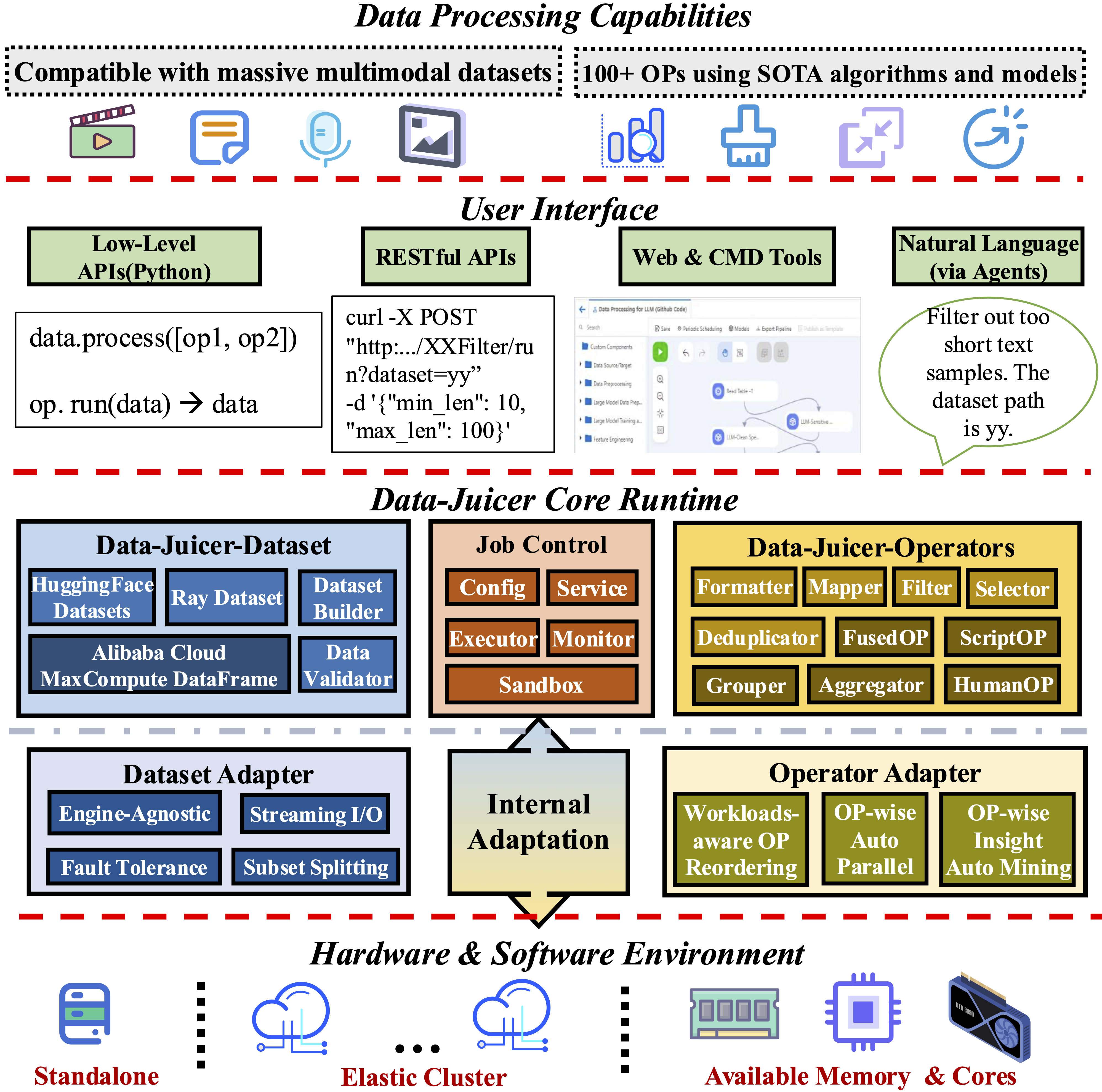
Why Data-Juicer?
-
Systematic & Reusable:
Empowering users with a systematic library of 100+ core OPs, and 50+ reusable config recipes and
dedicated toolkits, designed to
function independently of specific multimodal LLM datasets and processing pipelines. Supporting data analysis, cleaning, and synthesis in pre-training, post-tuning, en, zh, and more scenarios. -
User-Friendly & Extensible:
Designed for simplicity and flexibility, with easy-start guides, and DJ-Cookbook containing fruitful demo usages. Feel free to implement your own OPs for customizable data processing. -
Efficient & Robust: Providing performance-optimized parallel data processing (Aliyun-PAI\Ray\CUDA\OP Fusion),
faster with less resource usage, verified in large-scale production environments. -
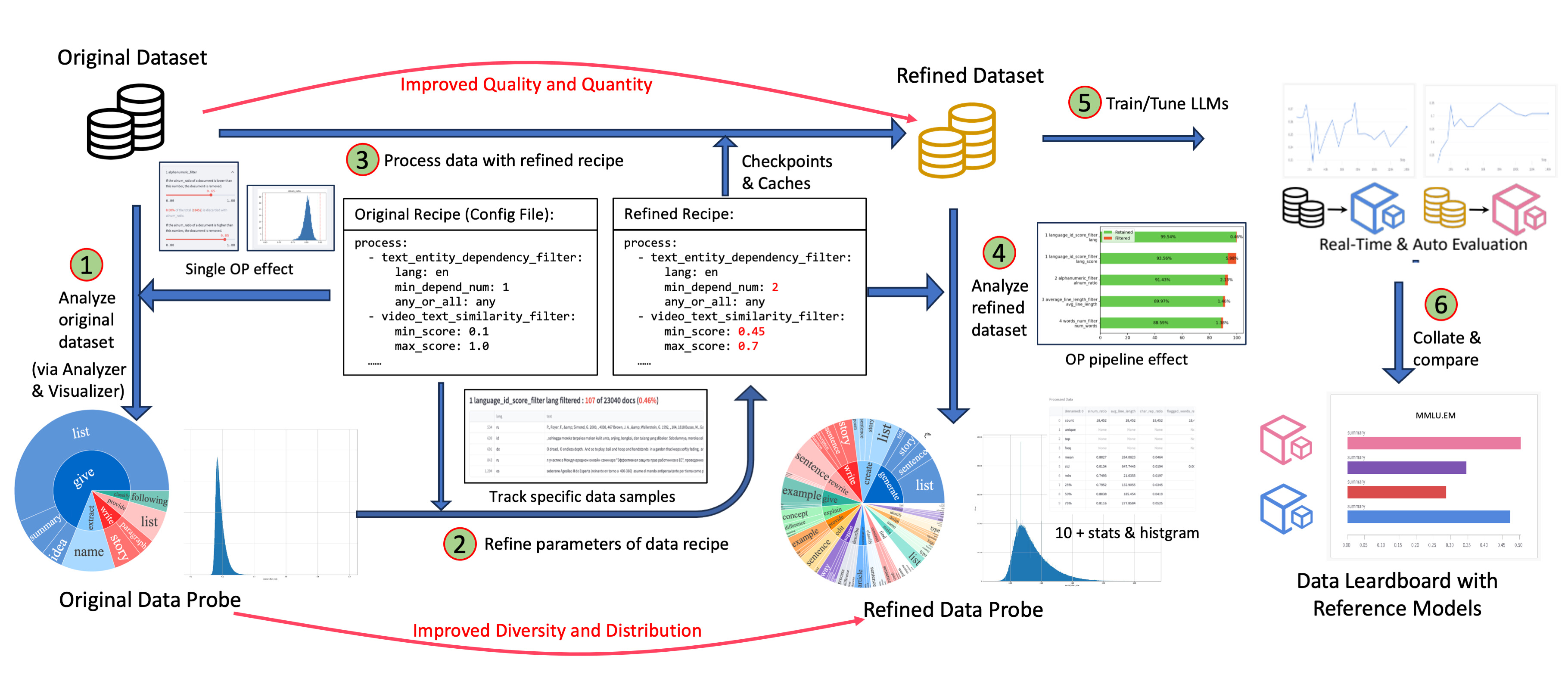
Effect-Proven & Sandbox: Supporting data-model co-development, enabling rapid iteration
through the sandbox laboratory, and providing features such as feedback loops and visualization, so that you can better understand and improve your data and models. Many effect-proven datasets and models have been derived from DJ, in scenarios such as pre-training, text-to-video and image-to-text generation.
Doucmentation
- Tutorial
- Useful documents
- Demos
- Tools
- Third-party
License
Data-Juicer is released under Apache License 2.0.
Contributing
We are in a rapidly developing field and greatly welcome contributions of new
features, bug fixes, and better documentation. Please refer to
How-to Guide for Developers.
Acknowledgement
Data-Juicer is used across various foundation model applications and research initiatives, such as industrial scenarios in Alibaba Tongyi and Alibaba Cloud’s platform for AI (PAI).
We look forward to more of your experience, suggestions, and discussions for collaboration!
Data-Juicer thanks many community contributors and open-source projects, such as
Huggingface-Datasets, Bloom, RedPajama, Arrow, Ray, …
References
If you find Data-Juicer useful for your research or development, please kindly cite the following works, 1.0paper, 2.0paper.
@inproceedings{djv1,
title={Data-Juicer: A One-Stop Data Processing System for Large Language Models},
author={Daoyuan Chen and Yilun Huang and Zhijian Ma and Hesen Chen and Xuchen Pan and Ce Ge and Dawei Gao and Yuexiang Xie and Zhaoyang Liu and Jinyang Gao and Yaliang Li and Bolin Ding and Jingren Zhou},
booktitle={International Conference on Management of Data},
year={2024}
}
@article{djv2,
title={Data-Juicer 2.0: Cloud-Scale Adaptive Data Processing for Foundation Models},
author={Chen, Daoyuan and Huang, Yilun and Pan, Xuchen and Jiang, Nana and Wang, Haibin and Ge, Ce and Chen, Yushuo and Zhang, Wenhao and Ma, Zhijian and Zhang, Yilei and Huang, Jun and Lin, Wei and Li, Yaliang and Ding, Bolin and Zhou, Jingren},
journal={arXiv preprint arXiv:2501.14755},
year={2024}
}
More data-related papers from the Data-Juicer Team:
>-
(ICML’25 Spotlight) Data-Juicer Sandbox: A Feedback-Driven Suite for Multimodal Data-Model Co-development
-
(CVPR’25) ImgDiff: Contrastive Data Synthesis for Vision Large Language Models
-
(Benchmark Data) HumanVBench: Exploring Human-Centric Video Understanding Capabilities of MLLMs with Synthetic Benchmark Data
-
(Benchmark Data) DetailMaster: Can Your Text-to-Image Model Handle Long Prompts?
-
(Data Synthesis) Diversity as a Reward: Fine-Tuning LLMs on a Mixture of Domain-Undetermined Data
-
(Data Synthesis) MindGYM: What Matters in Question Synthesis for Thinking-Centric Fine-Tuning?
-
(Data Scaling) BiMix: A Bivariate Data Mixing Law for Language Model Pretraining