GPU集群管理平台(GPU Cluster Management Platform)
GCMP
简介
GCMP(GPU Cluster Management Platform) GPU集群管理平台
代码基于Spring Boot,底层用k8s进行GPU分配和执行训练任务。
实现对多台GPU服务器文件、镜像、GPU调度的统一管理。
快速开始
GPU集群由一台master节点和多台从节点组成,最好以一台不带GPU的服务器作为master节点,如果没有的话把其中一台GPU服务器作为master节点也可以。
安装docker和nvidia-docker2
每台服务器上都要,配置参考请移步docker及nvidia-docker2安装步骤
如果主节点是不带GPU服务器的话,主节点上只需要docker,不需要nvidia-docker2。
请移步docker远程配置,开启java远程对docker的访问。
配置k8s
整体有点复杂,如果遇到问题google一下或者留言都可以。
配置master节点
请移步master配置
如果master节点是用的GPU服务器,并且希望master节点上的GPU也参与调度,执行以下命令
kubectl taint node k8s-master node-role.kubernetes.io/master-
配置从节点
请移步slave配置
数据库建表
建表脚本:gcmp.sql
启动主程序
java程序运行在主节点上,以下几个是关键配置:
-
gcmp.server-properties:在里面写上所有的带GPU的服务器。
-
gcmp.ftp-type:可以是ftp或者sftp,建议用ftp(比较快,并且经过比较完善的测试)。
-
gcmp.admin-name:可以设置管理员的用户名,默认是admin。
-
在gcmpConst中设置硬盘挂载位置DISK_MOUNT_PATH
第一次启动时先进行初始化,访问 http://127.0.0.1:8090/admin ,其会自动跳转到初始化页面。
预览图
用户 - 登录
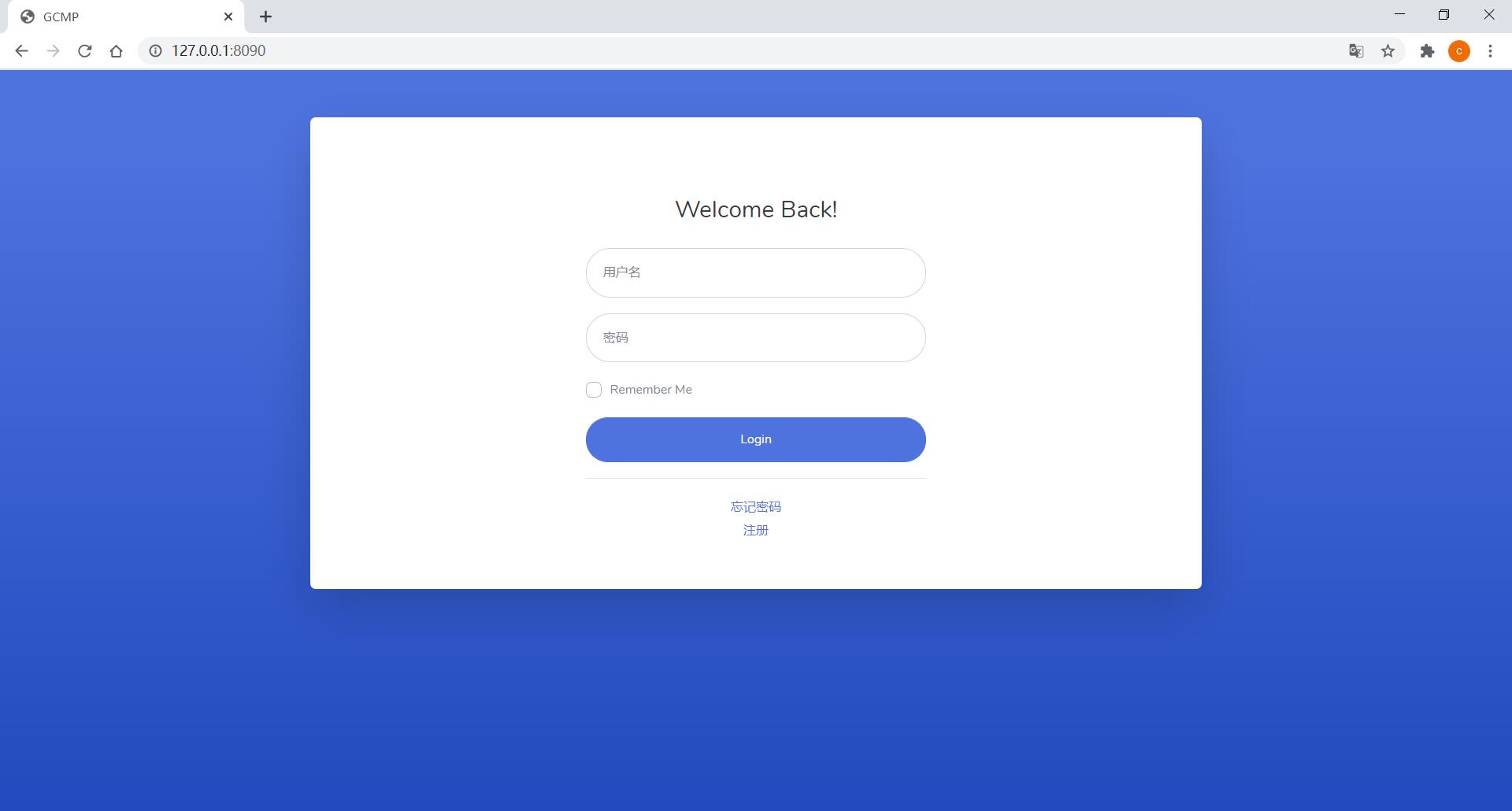
用户 - 我的任务
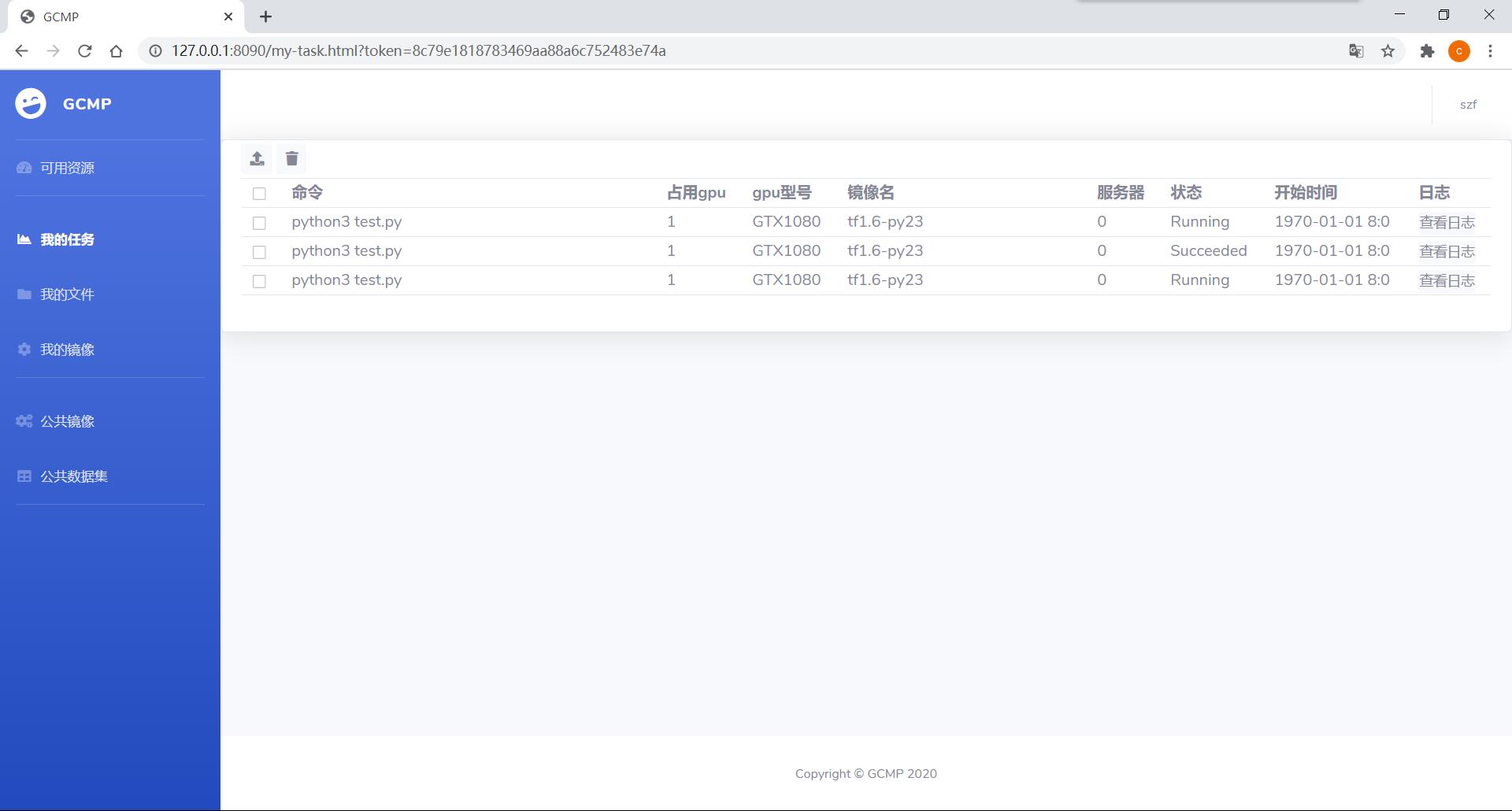
用户 - 我的文件
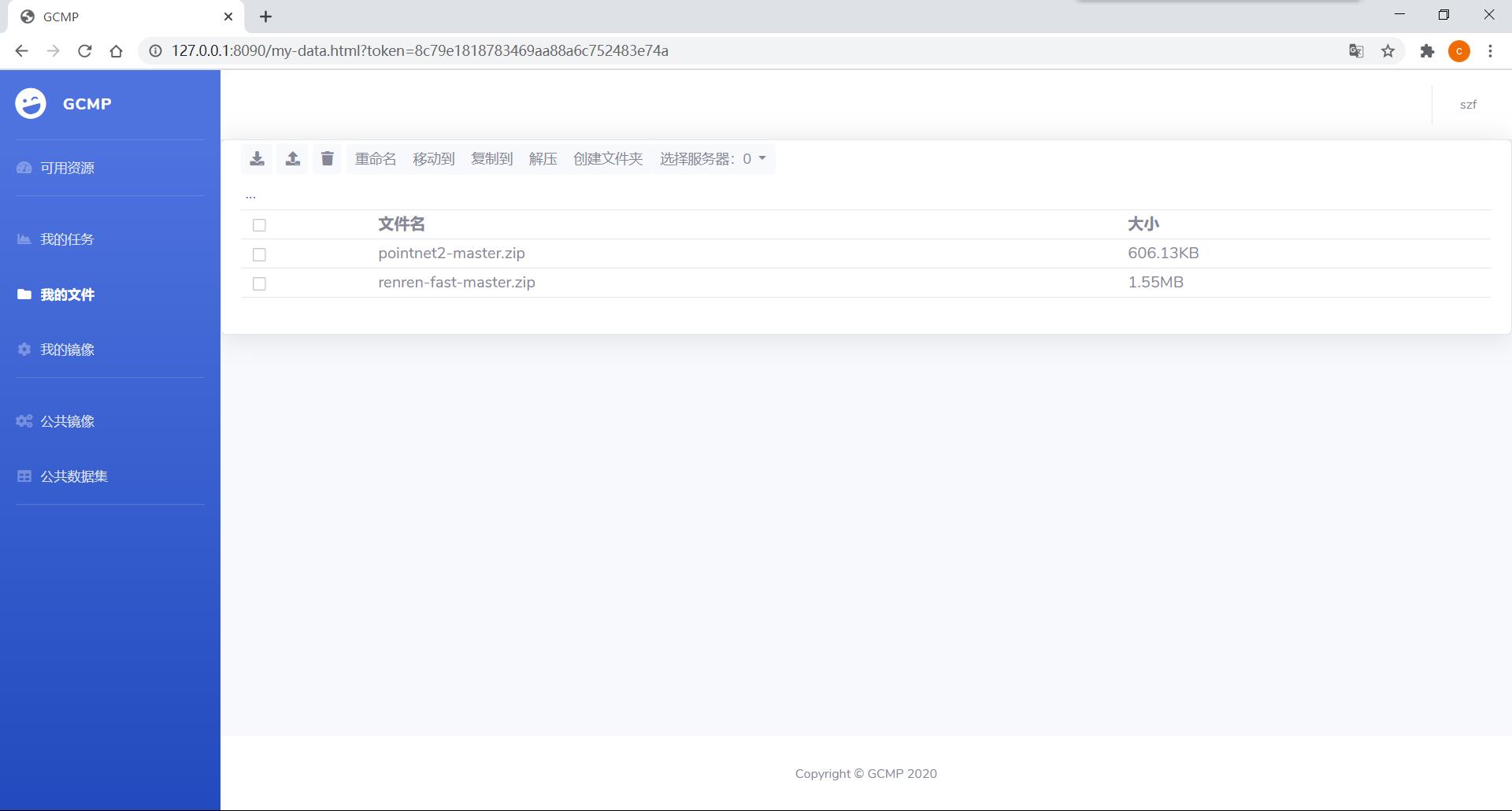
用户 - 我的镜像
用户 - 公共镜像
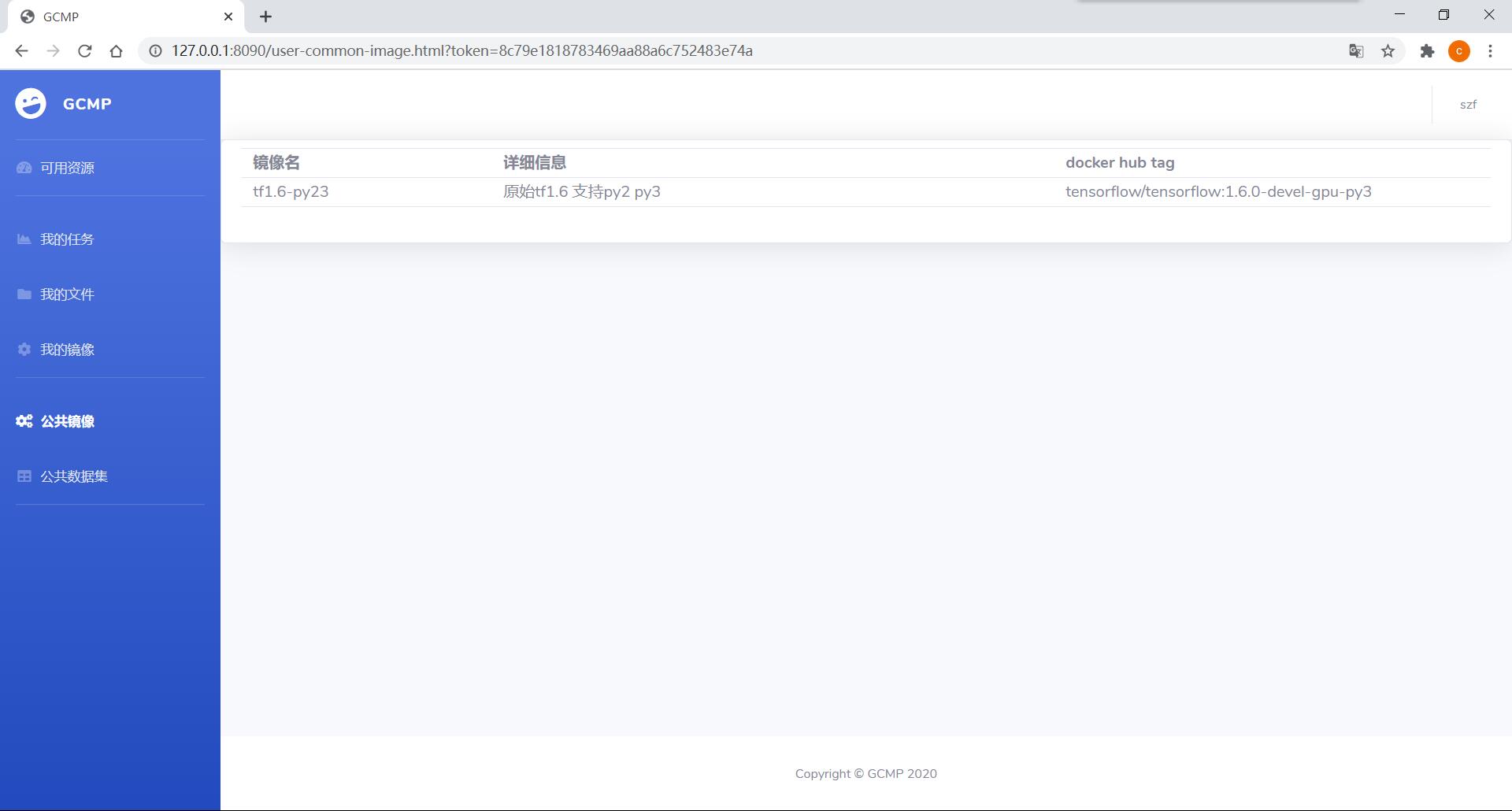
用户 - 公共数据集
管理员 - 用户管理
管理员 - 任务管理
管理员 - 文件管理
管理员 - 公共镜像管理
管理员 - 公共数据集管理
服务器空闲资源资源
使用指南
用户使用指南,请移步user guide
管理员使用指南,请移步 admin guide