PyParser is a data cleaning system for extracting the data from the content where is crawled by the web spiders.
项目介绍
项目简介
在常规的数据采集系统中,我们通常将爬虫采集部分和数据提取验证部分糅合在一个项目系统中,在爬虫进行采集的同时进行数据的提取、清洗、校验,这样的系统在数据规模较小、数据维度少、数据提取难度低的业务中可以实现快速轻便地开发。
然而,当数据规模较大,数据维度多,数据提取、清洗、校验难度高的场景下,上述系统可能会遇到以下问题:
流程分工不明确,当面对数据规模大且结构繁杂、且做足了反爬措施的网站时,爬虫工程师需要同时关注网站本身的采集部分和后续的数据处理部分。- 在业务没有明确时,针对同一种页面,在不同的时间点,极有可能出现增删字段的情况,删减字段相对容易,但当需求人员
需要你增加字段,在系统没有持久化原始网页的时候,就需要重新进行爬取(这时候你大概率会吐槽说:“wc,又要我重爬?”),当数据量大的时候,重新进行采集可能会增加项目的成本甚至导致项目延期。 - 在网页结构比较复杂,对数据不够敏感,数据提取、清洗、校验的难度较高时,经常会出现
部分字段漏解析、字段值解析错误的情况,如果系统没有持久化原始网页,就可能会导致重新采集。流程分工比较明确的情况是,爬虫工程师只需要负责网站网页的采集和应对反爬措施,数据的处理交由数据工程师进行。
PyParser框架正是为了解决以上遇到的问题,总的而言,PyParser可以做到:
- 提供类似Scrapy加载爬虫逻辑脚本的方式,可动态加载数据提取逻辑脚本,使得数据采集和数据处理分工更明确,不仅仅是代码层面上进行隔离,更是从业务分工上隔离。
- 提供持久化原始网页的功能,减少因数据处理流程失误或业务不明确导致重爬的成本。
- 提供数据解析、校验功能,可自定义任务的解析脚本、数据校验规则。
- 提供数据入库的功能,当数据通过校验时,可进行数据入库操作。
- 可分布式、增量扩展消费者,当网页数据量多的时候,可以动态增加下游消费者,提高数据处理的速度。
架构设计
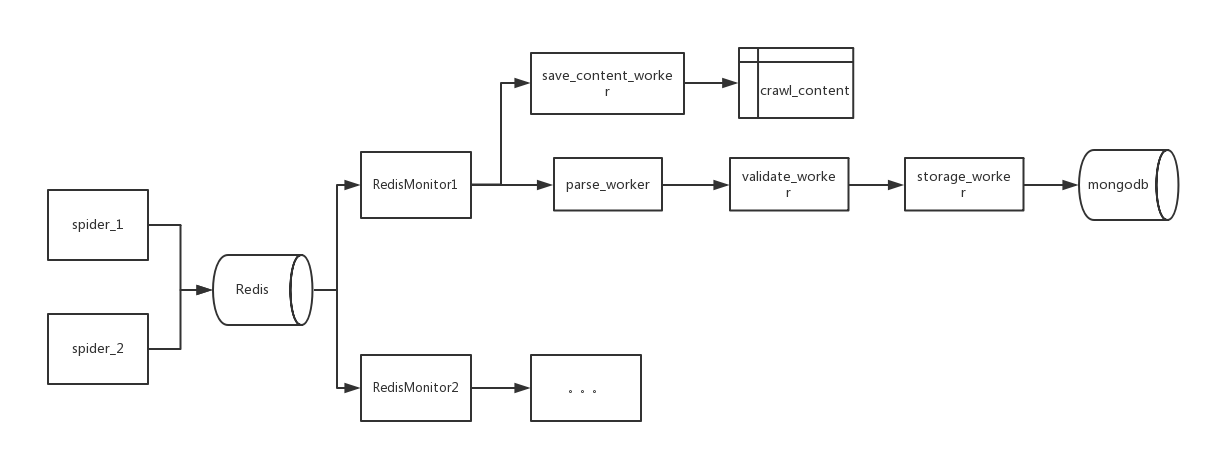
系统的主要部分有:
- RedisMonitor:监控爬虫的结果队列,从爬虫的结果队列中获取结果并推送给下游处理。
- save_content_worker:网页持久化消费者,用于将原始网页进行持久化。
- parse_worker:数据解析消费者,加载解析脚本,对原始网页进行解析。
- validate_worker:数据校验消费者,加载校验脚本,对解析结果进行进一步校验。
- storage_worker:入库消费者,对通过校验的数据进行入库处理。
To-Do-List
- [ ] 使用环境变量设置配置。
- [ ] 增加开发业务脚本流程相关工具。
- [ ] 持久化内容删除策略设计及实现。
- [ ] 增加详细配置文档。
- [ ] 增加使用对象存储进行持久化。