Web crawling with IP rotation via Tor
TorCrawler
This project is not maintained and was intended mainly for learning purposes. Use at your discretion and feel free to fork!
Requests with IP rotation; TorCrawler is a layer on top of Python’s requests module that routes traffic through Tor.
Sometimes you need to crawl a big directory and sometimes that means making a lot of requests. You may want to brute force it and run the risk of getting your IP blacklisted (just go to a coffee shop, right?), but probably not. You probably just want to deploy your crawler on an cloud instance and forget about it. If so, this one’s for you.
Usage
IMPORTANT: This module will only work with Python 3 due to problems arising from cross-usage of sockets. In the same vein, instantiating multiple instances of TorCrawler leads to SOCKS failure because the port is already being used. So for now, you should only create one instance and use Python 3.
To start crawling from scratch, make sure you have Tor set up and that you have it configured properly (see below section called “Configuring Tor”). Once you do, boot it up and then load a TorCrawler instance.
from TorCrawler import TorCrawler
crawler = TorCrawler()
crawler.ip
>>> '113.10.95.15'
# Make a GET request (returns a BeautifulSoup object unless use_bs=False)
data = crawler.get("http://somewebsite.com")
data
>>> <!DOCTYPE doctype html>...
# TorCrawler will, by default, rotate every n_requests.
# If you want to manually rotate your IP, you can do that any time.
crawler.rotate()
crawler.ip
>>> '121.150.155.19'
Options
| arg | type | default | description |
|---|---|---|---|
| socks_port | int | 9050 | Port on which Tor is running a proxy server. |
| socks_host | str | ‘localhost’ | Your Tor host. |
| ctrl_port | int | 9051 | The port at which Tor’s controller can be accessed. |
| ctrl_pass | str | os.environ[“TOR_CTRL_PASS”] | Plaintext password for accessing controller (hashed password stored in your torrc file). |
| n_requests | int | 24 | Number of consecutive requests that will be made between rotations. |
| use_bs | bool | True | Return BeautifulSoup objects from your GET requests. False returns requests objects instead. |
| use_tor | bool | True | Use Tor when making requests. |
| rotate_ips | bool | True | Automatically ask client to redraw the Tor circuit every n_requests. |
| enforce_rotate | bool | True | Requires your IP to change when rotating. |
| enforce_limit | int | 3 (max 100) | Redraw until IP changes or this number of redraws is performed. |
Tor Background
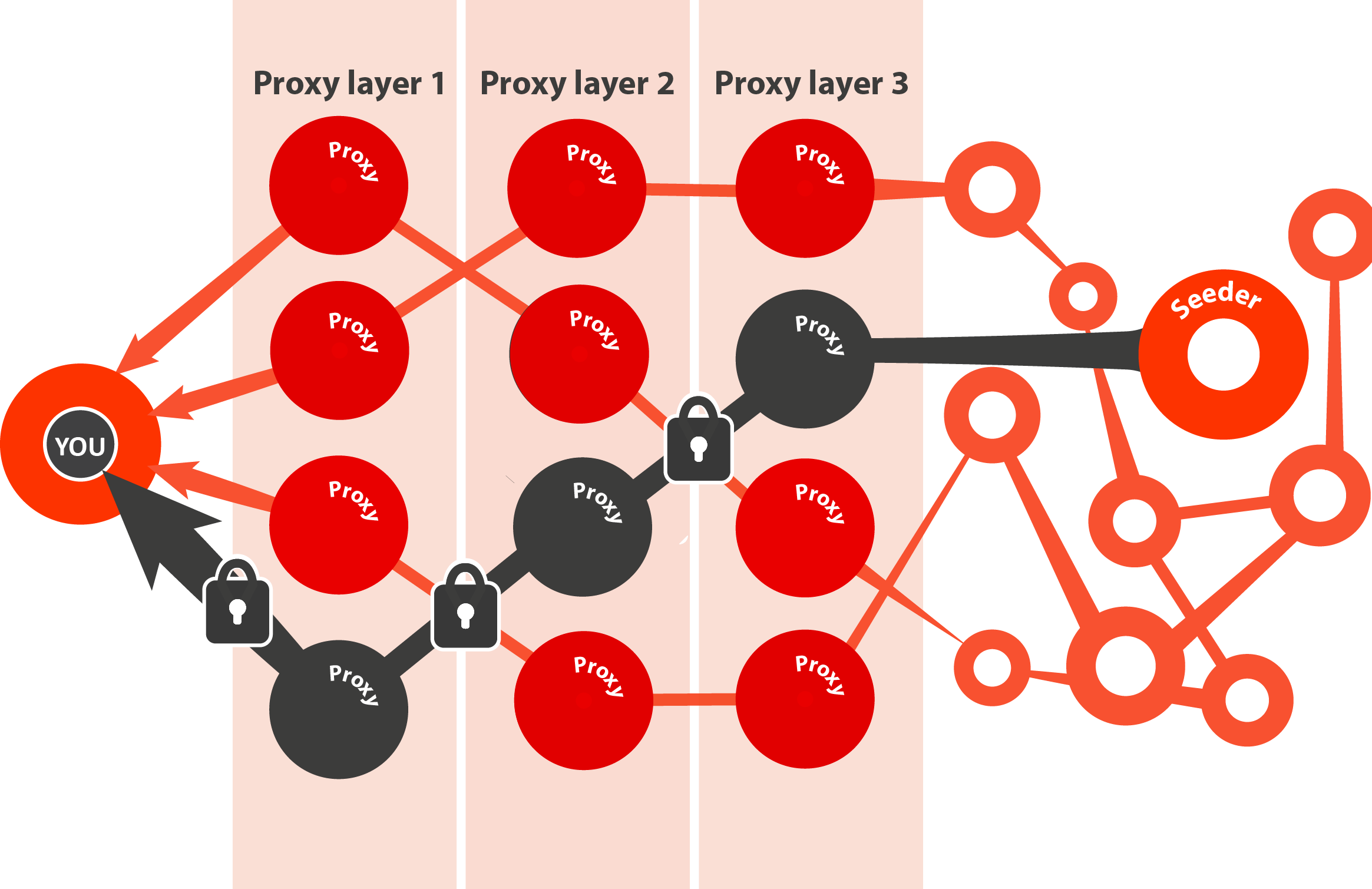
Tor draws a route between your computer and the internet. This route (or circuit) is a series of Tor relays (a.k.a. nodes), which are proxy servers running Tor and routing traffic between Tor clients (e.g. your computer) and the internet.
Once the circuit is drawn, a request is made from your machine. This request is encrypted N times, where N is the number of nodes in your circuit. As the request reaches each node, it decrypts the outermost layer of encryption and passes the traffic to the next relay. The final relay makes the request to the server, recieves the response, and shuttles the traffic (again encrypted N times) back along the circuit it came from. This process is sometimes called “onion routing” because each layer of encryption is “peeled back” at each subsequent node, sort of like an onion.
Once you boot up Tor, it will automatically configure a circuit and your proxy IP will be the last node in the circuit. If you want to use Tor in your every day browsing, you can check out the Tor browser (but keep in mind there are only about 7000 relay nodes so please don’t download large files). Also note that Tor is technically anonymous browsing, but this is a very grey area, especially if exit nodes are compromised or you are browsing in an identifiable way. If you are concerned with anonymous browsing, don’t use the same circuit to repeatedly Google yourself and log in to your bank account.
TorCrawler uses a Tor client (i.e. not the browser), which we will configure now.
Configuring Tor
Tor is fairly straightforward to set up and run as a proxy server for web requests. First, download the Tor browser. This will install Tor alongside the browser (we will only be using the client, not the browser). This guide will assume you are on a UNIX system. The config file is located at /etc/tor/torrc. Tor can be started as a service using service tor start on Linux. For OSX installation, check this. Before proceeding, we need to check on two configurations for our crawler:
SOCKS5
TorCrawler will send the Tor client signals via the SOCKS5 protocol. By default, Tor will boot running SOCKS5 on localhost via port 9050. You can change these settings if you need to.
Tor Controller
The Tor service can be sent commands via the control port. The command we will use for the crawler is called NEWNYM, which tells Tor to redraw the circuit. Note that this does not always mean your circuit’s exit node will have a new IP (Tor could choose a different route, but keep the exit node in place), so we may need to call NEWNYM multiple times to get a fresh IP. The controller is not automatically configured because opening it makes you susceptible to attacks. For this reason, we will only want to open the port once we have a hashed password in place. To generate a tor-compatible hashed password, run:
tor --hash-password mypassword
And save the hashed password in your torrc file on the line that begins with HashedControlPassword. Also be sure to uncomment the line that says ControlPort 9051. When sending a command to the tor controller, you will use the plain text version of this hashed password; I recommend saving it as an environmental variable in your bash profile.