WebHunger is an extensible, full-scale crawler framework that supports distributed crawling, aiming at getting users focused on web page parsing without concerning for the crawling process.
正在开发中…
为什么要写WebHunger
首先,总结下当前各类爬虫,其特点以及对应的开源爬虫框架
| 爬虫类型 | 爬取数量 | 被禁风险 | 开源框架 |
|---|---|---|---|
| 搜索引擎爬虫 | 未知 | 最低 | Nutch |
| 垂直型爬虫 | 确定 | 适中 | WebMagic SpiderMan |
| 全站式爬虫 | 未知 | 最高 | 无 |
- 关于爬取数量:如果爬取前,我们能事先知道我们要爬取的内容是什么,大概有多少数据量,那么我们就很容易知道当前爬虫的爬取效果怎么样;反之,当我们不知道这些信息的时候,对爬虫爬取效果的好坏就比较难评定了,所以,这就是搜索引擎爬虫与全站式爬虫的一大难题所在。
- 关于被禁风险:由于搜索引擎爬虫是对整个互联网进行爬取,所以很容易可以做到对不同站点进行轮流爬取,避免对某个站点频繁爬取,从而降低被禁风险;而对于全站式爬虫来说,因为是对于一个站点的全部网页进行爬取,所以被禁风险最大。
- 关于开源框架:在搜索引擎领域,有大名鼎鼎的Nutch;在垂直型爬虫领域,开源框架更多,例如WebMaigc SpiderMan等优秀框架;而在全站式爬虫领域,我未找到相关框架。当然,对另外两种爬虫的适当变形,可以满足一定需求,但效果不尽理想。
此外,实验室平日工作需要全站式爬虫。在工作过程中,也发现其他同学想要更多数据进行实验,但苦于爬虫系统上手不易,需要通过我的帮助。于是就诞生了开发WebHunger的想法。
WebHunger是什么
WebHunger名字由单词Web与Hunger([ˈhʌŋɡɚ])组成,寓意着对网页数据的渴望,旨在爬取更多的数据
WebHunger 是一个可扩展的、支持分布式爬取的全站式爬虫框架,旨在使用户专注
于页面处理逻辑的开发,而无需关心爬取过程。用户只需提交待爬取网站链接与页面处理类给框架,爬取完毕后,框架会及时将爬取结果返回给用户,用户无需掌握分布式编程、无需了解爬虫工作机制,大大降低了用户使用门槛。
为了使用户操作简便,WebHunger提供了一个基于Web UI的管理监控界面,部分截图如下所示:
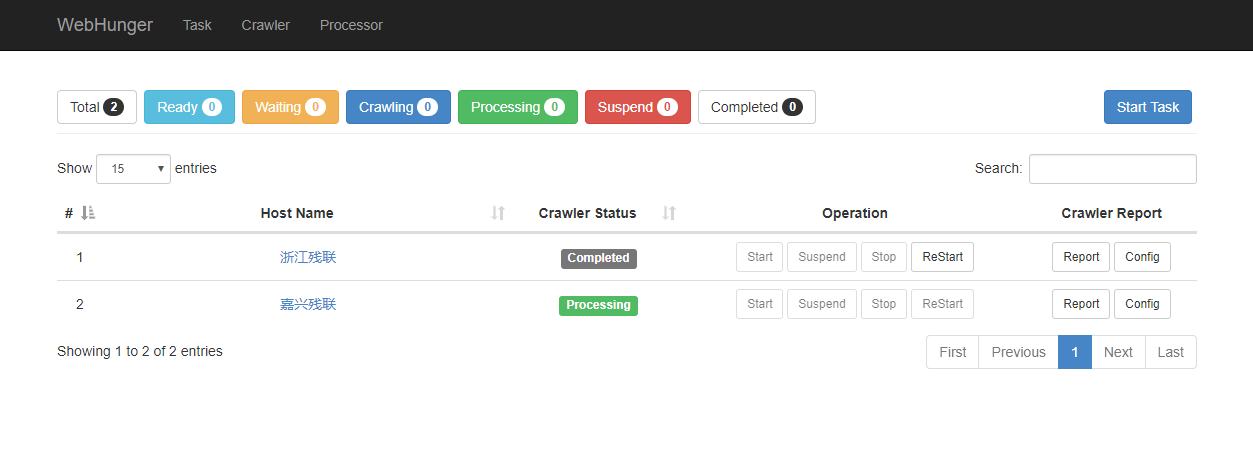
以上是站点控制界面,可以对站点进行开始爬取、暂停、重新爬取等操作
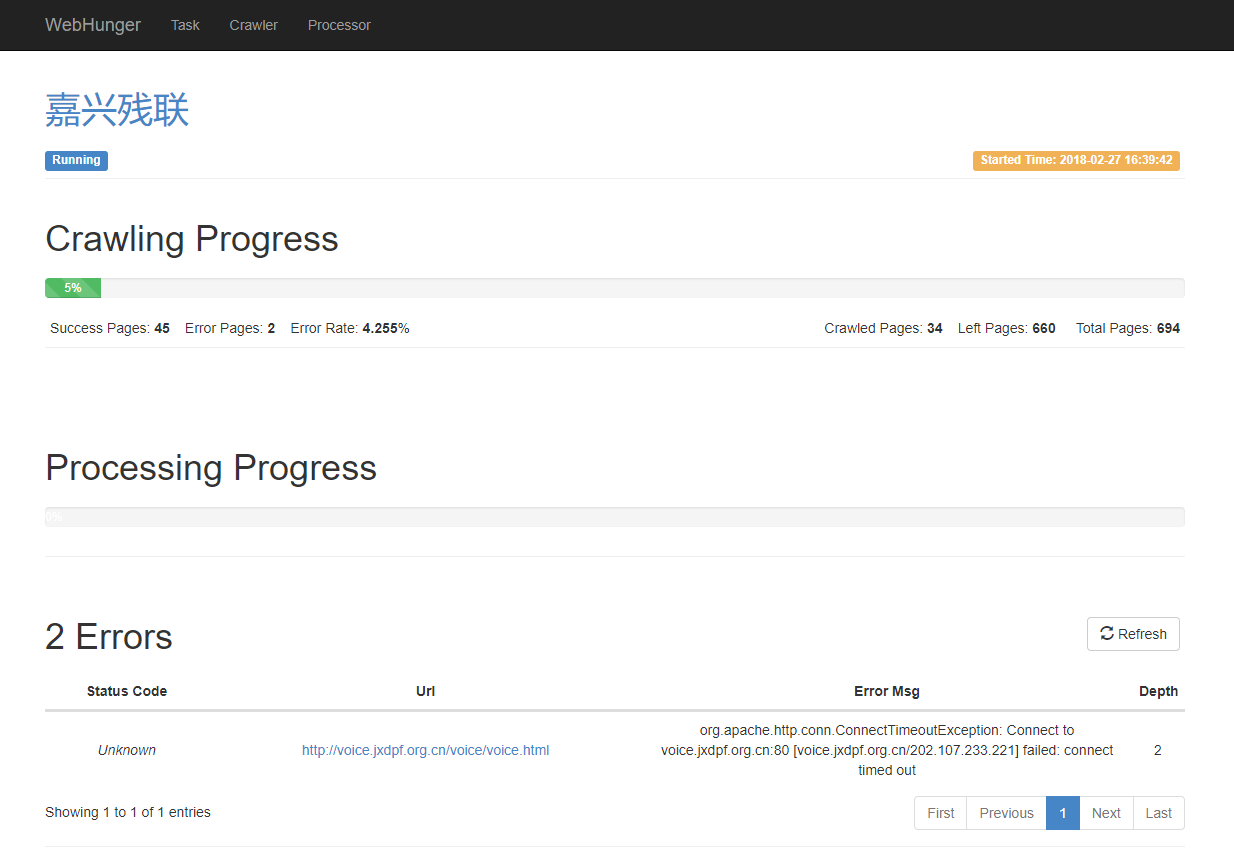
以上是站点爬取过程中的界面,可以看到当前站点的爬取进度、页面处理进度,以及爬取错误的链接等信息
WebHunger架构
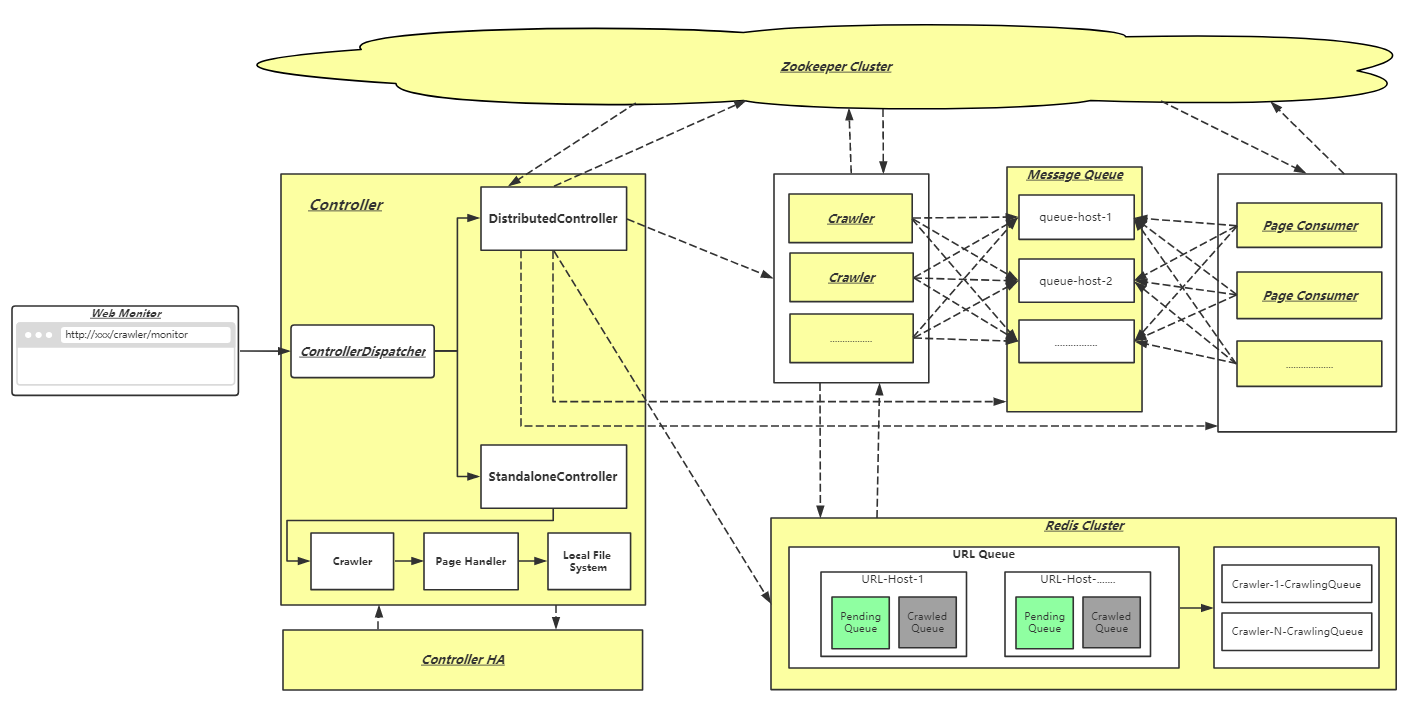
上图所有底色为黄色的组件都可以独立部署到任意服务器运行;实线表示本地调用;虚线表示远程调用
WebHunger共有以下几大部分组成:
- Controller: 负责待爬站点的管理
- Crawler:按照Controller指定的URL调度策略从Redis获取URL进行爬取,并将爬取结果放入消息队列
- Page Consumer: 从消息队列拉取网页消息,调用用户自定义的页面处理类
- ZooKeeper Cluster: 做站点状态存储、服务发现、分布式锁等工作
- RocketMQ: 存储爬取的网页信息与分发工作
- Redis Cluster: 负责存储各站点待爬URL以及URL过滤去重
- Web Console: 基于Web UI的监控平台