Wgit enables you to crawl and extract the data you want from the web
Wgit
![]()
![]()


Wgit is a HTML web crawler, written in Ruby, that allows you to programmatically extract the data you want from the web.
Wgit was primarily designed to crawl static HTML websites to index and search their content - providing the basis of any search engine; but Wgit is suitable for many application domains including:
- URL parsing
- Document content extraction (data mining etc)
- Recursive website crawling (indexing, statistical analysis etc)
Wgit provides a high level, easy-to-use API and DSL that you can use in your own applications and scripts.
Check out this demo search engine - built using Wgit, Sinatra and MongoDB - deployed to fly.io. Try searching for something that’s Ruby related like “Matz” or “Rails”.
Table Of Contents
- Usage
- Why Wgit?
- Why Not Wgit?
- Installation
- Documentation
- Executable
- License
- Contributing
- Development
Usage
Let’s crawl a quotes website extracting its quotes and authors using the Wgit DSL:
require 'wgit'
require 'json'
include Wgit::DSL
start 'http://quotes.toscrape.com/tag/humor/'
follow "//li[@class='next']/a/@href"
extract :quotes, "//div[@class='quote']/span[@class='text']", singleton: false
extract :authors, "//div[@class='quote']/span/small", singleton: false
quotes = []
crawl_site do |doc|
doc.quotes.zip(doc.authors).each do |arr|
quotes << {
quote: arr.first,
author: arr.last
}
end
end
puts JSON.generate(quotes)
Which outputs:
[
{
"quote": "“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”",
"author": "Jane Austen"
},
{
"quote": "“A day without sunshine is like, you know, night.”",
"author": "Steve Martin"
},
...
]
Great! But what if we want to crawl and store the content in a database, so that it can be searched? Wgit makes it easy to index and search HTML using MongoDB (by default):
require 'wgit'
include Wgit::DSL
Wgit.logger.level = Logger::WARN
ENV['WGIT_CONNECTION_STRING'] = 'mongodb://user:password@localhost/crawler'
start 'http://quotes.toscrape.com/tag/humor/'
follow "//li[@class='next']/a/@href"
extract :quotes, "//div[@class='quote']/span[@class='text']", singleton: false
extract :authors, "//div[@class='quote']/span/small", singleton: false
index_site
search 'prejudice'
The search call (on the last line) will return and output the results:
Quotes to Scrape
“I am free of all prejudice. I hate everyone equally. ”
http://quotes.toscrape.com/tag/humor/page/2/
...
Using a database client, we can see that the two web pages have been indexed, along with their extracted quotes and authors:
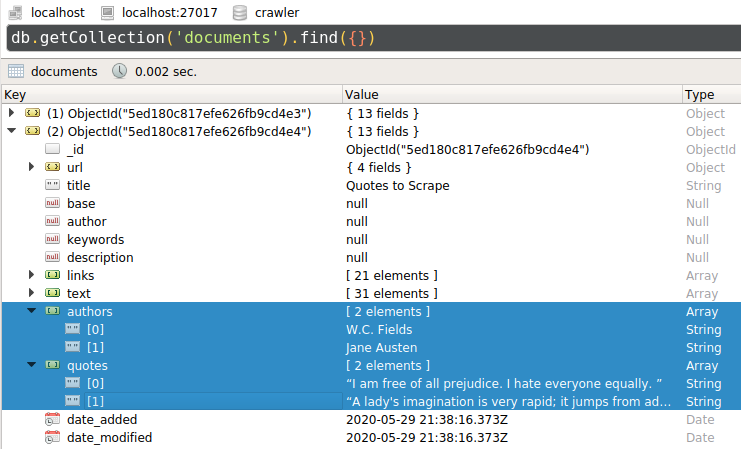
The DSL makes it easy to write scripts for experimenting with. Wgit’s DSL is simply a wrapper around the underlying classes. For comparison, here is the quote example re-written using the Wgit API instead of the DSL:
require 'wgit'
require 'json'
crawler = Wgit::Crawler.new
url = Wgit::Url.new('http://quotes.toscrape.com/tag/humor/')
quotes = []
Wgit::Document.define_extractor(:quotes, "//div[@class='quote']/span[@class='text']", singleton: false)
Wgit::Document.define_extractor(:authors, "//div[@class='quote']/span/small", singleton: false)
crawler.crawl_site(url, follow: "//li[@class='next']/a/@href") do |doc|
doc.quotes.zip(doc.authors).each do |arr|
quotes << {
quote: arr.first,
author: arr.last
}
end
end
puts JSON.generate(quotes)
Why Wgit?
There are many other HTML crawlers out there so why use Wgit?
- Wgit has excellent unit testing, 100% documentation coverage and follows semantic versioning rules.
- Wgit excels at crawling an entire website’s HTML out of the box. Many alternative crawlers require you to provide the
xpathneeded to follow the next URLs to crawl. Wgit by default, crawls the entire site by extracting its internal links pointing to the same host - noxpathneeded. - Wgit allows you to define content extractors that will fire on every subsequent crawl; be it a single URL or an entire website. This enables you to focus on the content you want.
- Wgit can index (crawl and save) HTML to a database making it a breeze to build custom search engines. You can also specify which page content gets searched, making the search more meaningful. For example, here’s a script that will index the Wgit wiki articles:
require 'wgit'
ENV['WGIT_CONNECTION_STRING'] = 'mongodb://user:password@localhost/crawler'
wiki = Wgit::Url.new('https://github.com/michaeltelford/wgit/wiki')
# Only index the most recent of each wiki article, ignoring the rest of Github.
opts = {
allow_paths: 'michaeltelford/wgit/wiki/*',
disallow_paths: 'michaeltelford/wgit/wiki/*/_history'
}
indexer = Wgit::Indexer.new
indexer.index_site(wiki, **opts)
- Wgit supports different databases through the use of “adapter” classes, which you can write to support your own database of choice.
- Wgit’s built in indexing methods will by default, honour a site’s
robots.txtrules. There’s also a handyrobots.txtparser that you can use in your own code.
Why Not Wgit?
So why might you not use Wgit, I hear you ask?
- Wgit doesn’t allow for webpage interaction e.g. signing in as a user. There are better gems out there for that.
- Wgit can parse a crawled page’s Javascript, but it doesn’t do so by default. If your crawls are JS heavy then you might best consider a pure browser-based crawler instead.
- Wgit while fast (using
libcurlfor HTTP etc.), isn’t multi-threaded; so each URL gets crawled sequentially. You could hand each crawled document to a worker thread for processing - but if you need concurrent crawling then you should consider something else.
Installation
Only MRI Ruby is tested and supported, but Wgit may work with other Ruby implementations.
Currently, the supported range of MRI Ruby versions is:
ruby '~> 3.0' a.k.a. between Ruby 3.0 and up to but not including Ruby 4.0. Wgit will probably work fine with older versions but best to upgrade if possible.
Using Bundler
$ bundle add wgit
Using RubyGems
$ gem install wgit
Verify
$ wgit
Calling the installed executable will start an REPL session.
Documentation
Executable
Installing the Wgit gem adds a wgit executable to your $PATH. The executable launches an interactive REPL session with the Wgit gem already loaded; making it super easy to index and search from the command line without the need for scripts.
The wgit executable does the following things (in order):
require wgit- Loads an
.envfile (if one exists in either the local or home directory, which ever is found first) eval’s a.wgit.rbfile (if one exists in either the local or home directory, which ever is found first)- Starts an interactive shell (using
pryif it’s installed, orirbif not)
The .wgit.rb file can be used to seed fixture data or define helper functions for the session. For example, you could define a function which indexes your website for quick and easy searching everytime you start wgit.
License
The gem is available as open source under the terms of the MIT License. See LICENSE.txt for more details.
Contributing
Bug reports and feature requests are welcome on GitHub. Just raise an issue, checking it doesn’t already exist.
The current road map is rudimentally listed in the Road Map wiki page. Maybe your feature request is already there?
Before you consider making a contribution, check out CONTRIBUTING.md.
Development
After checking out the repo, run the following commands:
gem install bundler toysbundle install --jobs=3toys setup
And you’re good to go!
Tooling
Wgit uses the toys gem (instead of Rake) for task invocation. Always run toys as bundle exec toys. For a full list of available tasks a.k.a. tools, run bundle exec toys --tools. You can search for a tool using bundle exec toys -s tool_name. The most commonly used tools are listed below…
Run bundle exec toys db to see a list of database related tools, enabling you to run a Mongo DB instance locally using Docker. Run bundle exec toys test to execute the tests.
To generate code documentation locally, run bundle exec toys yardoc. To browse the docs in a browser run bundle exec toys yardoc --serve. You can also use the yri command line tool e.g. yri Wgit::Crawler#crawl_site etc.
To install this gem onto your local machine, run bundle exec toys install and follow the prompt.
Console
You can run bundle exec toys console for an interactive shell using the ./bin/wgit executable. The bundle exec toys setup task will have created an .env and .wgit.rb file which get loaded by the executable. You can use the contents of this gist to turn the executable into a development console. It defines some useful functions, fixtures and connects to the database etc. Don’t forget to set the WGIT_CONNECTION_STRING in the .env file.